# webWorker+indexedDB性能优化
lastUpdated: 2023-9-01
# 名词解释
webworker: 就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。
indexedDB: 随着浏览器的功能不断增强,越来越多的网站开始考虑,将大量数据储存在客户端,这样可以减少从服务器获取数据,直接从本地获取数据。现有的浏览器数据储存方案,都不适合储存大量数据:Cookie 的大小不超过4KB,且每次请求都会发送回服务器;LocalStorage 在 2.5MB 到 10MB 之间(各家浏览器不同),而且不提供搜索功能,不能建立自定义的索引。所以,需要一种新的解决方案,这就是 IndexedDB 诞生的背景。
# webworker
我们使用webworker的时候要注意以下几点:
同源限制: 分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
DOM限制: Worker 线程所在的全局对象,与主线程不一样,无法读取主线程所在网页的 DOM 对象,也无法使用document、window、parent这些对象。但是,Worker 线程可以navigator对象和location对象。
通信联系: Worker 线程和主线程不在同一个上下文环境,它们不能直接通信,必须通过消息完成。
脚本限制: Worker 线程不能执行alert()方法和confirm()方法,但可以使用 XMLHttpRequest 对象发出 AJAX 请求。
文件限制: Worker 线程无法读取本地文件,即不能打开本机的文件系统(file://),它所加载的脚本,必须来自网络。
# indexedDB
键值对储存: IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
异步: IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
支持事务: IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
同源限制: IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
储存空间大: IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
支持二进制储存: IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
# 如何提高应用性能?
在这里我推荐使用 dexie ,这是一个已经封装好的操作indexedDB的工具库。
为什么不使用原生API?下面是摘抄MDN上的原话,传送门 (opens new window)。
注意:IndexedDB API是强大的,但对于简单的情况可能看起来太复杂。如果你更喜欢一个简单的API,请尝试 localForage (opens new window)、dexie.js (opens new window)、PouchDB (opens new window)、idb (opens new window)、idb-keyval (opens new window)、JsStore (opens new window) 或者 lovefield (opens new window) 之类的库,这些库使 IndexedDB 对开发者来说更加友好。
对于使用indexed当作本地缓存数据库使用的话,原生API的功能对于我们来说实在有些大材小用了。像事务等功能,缓存场景并不适用,所以我更推荐使用现成已经有的轮子来对数据库进行增删改查,这样可以大大减少我们的代码量,同时可以大幅度降低代码逻辑复杂度。
问: 本地数据库和远程数据库数据一致性怎么保证呢?
答:所以个人其实更推荐将一些改动幅度比较小的api缓存到本地数据库中。
如果api更改的很频繁,并不建议让其缓存到本地数据库中。
问:那有一些场景既不频繁,但偶尔也有更改的场景应该如何处理呢?
答:可以先使用本地数据库,然后在fetch api进行比对,如果比对结果无diff不做任何处理,
如果有diff的话,我们更新本地数据库,同时rerender页面。
问:这样的话虽然页面展示出来了,但是fetch时候依然占用主线程,导致主线程挂起?
答:所以另一个主角webworker迈着正步向我们走来了,可以起一个webworker代替我们进行
fetch和diff,这样既不需要占用主线程,还可以帮我们搬砖。Wow...
# 创建indexedDB
// 实例化一个数据库 数据库名称是tikhawk_db
const db = new Dexie('dbname') as ILocalIndexDB;
// 在dexie框架中我们并不需要管理复杂的版本系统,默认使用框架内部的处理,使用1即可。
// 在数据库中加了一个数据表 common, 同时指定主键 stamp
db.version(1).stores({
common: 'stamp',
});
// 继续封装我们common表的操作。
// why? 缓存数据库并不像服务端数据库一样,我们需要固定格式的数据,我更推荐使用一个表才缓存数据。
// 这样我们可以更高性能的根据主键来获取我们缓存的整个数据对象。
export const dbPut = <T>(data: T, stamp: string) => {
db.common.put({data, stamp})
}
export const dbGet = (stamp: string) => {
return db.common.get(stamp);
}
//以上操作一个数据库和数据库都已经建好了, 下面来使用。
const enum IndexedDBStampEnum {
PRODUCT = "product",
}
// 向数据表中插入一条主键为product的记录,如果该记录不存在则创建,如果该记录存在则覆盖。
await dbPut({name: "pencil", price: 100}, IndexedDBStampEnum.PRODUCT);
// 查询数据表中主键为product的记录。
const {data, stamp} = await dbGet(IndexedDBStampEnum.PRODUCT);
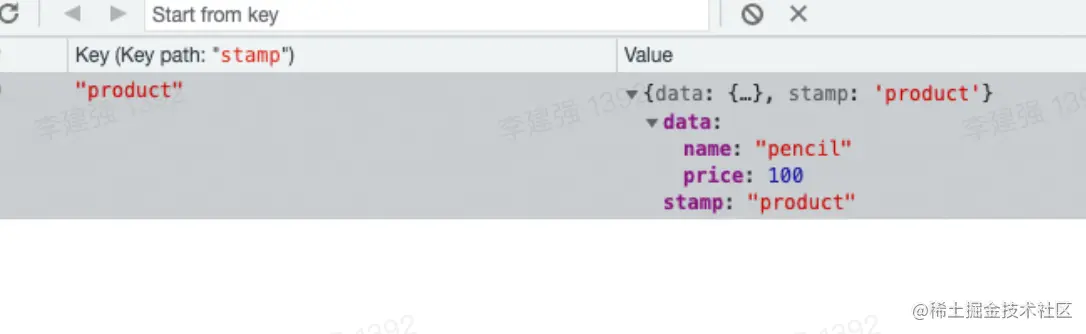
上面已经成功创建一个名称为 "dbname" 的数据库。
在tikhawk_db数据库中创建了一个名称为"common"的数据表。
并插入了一条 {name: "pencil", price: 100}的记录。
打开控制台看下数据库中是否有这条记录。
# 创建web Worker
// 在worker.js中导出一个worker的方法
export function entitiesWorker() {
// 当收到主线程来信的时候需要做的处理
self.onmessage = e => {
// 请求接口
fetch(self.location.origin + '/api/entities', {
method: 'GET',
}).then( r => r.json()).then(
r => {
// 进行比对
// 或者使用深拷贝
if(JSON.stringify(e.data) === JSON.stringify(r.data[0])) {
// 不需要更新
self.postMessage({
isUpdate: false,
});
} else {
// 需要更新
self.postMessage({
isUpdate: true,
data: r.data,
});
}
}
)
}
}
// 主线程
// 由于web Worker只能通过url引入,同时还有同源策略所以需要我们自己处理worker.js文件
// transWorker 是我们转worker的工具
// 将worker转成一个IIFE之后封装成一个blob 然后传入worker。
export const transWorker = (worker) => {
let blob = new Blob([ "(" + worker.toString() + ')()'], {type: "application/javascript"});
return new Worker(URL.createObjectURL(blob));
}
let apiWorker = transWorker(entitiesWorker);
// 经过上面一番简单的折腾我们的worker就建好了
# web Worker和indexedDB通信
上面我们已经写好了web Worker 和 indexedDB,接下来结合两者进行本地数据缓存和单开线程进行数据diff及更新。
const {data} = await dbGet(IndexedDBStampEnum.PRODUCT);
// 如果本地数据库中有数据
if(data) {
// 将本地缓存数据给State
this.setState({ data });
// 单开worker线程
let apiWorker = transWorker(entitiesWorker);
// 由于worker无法访问indexedDB,所以需要手动将数据传给worker线程
apiWorker.postMessage(data);
// 等待worker响应
apiWorker.onmessage = e => {
// 如果数据有diff
if(e.data.isUpdate) {
// 更新数据库及rerender页面
dbPut(e.data.data, IndexedDBStampEnum.PRODUCT);
this.setState({ data: e.data.data });
}
//关闭线程
apiWorker.terminate();
}
} else {
//没有数据则执行api拉取,不要忘记在api层更新indexedDB的数据。
await this.getState();
}
这样api就在本地缓存好了,我们看一下大概可以提升多少性能呢?
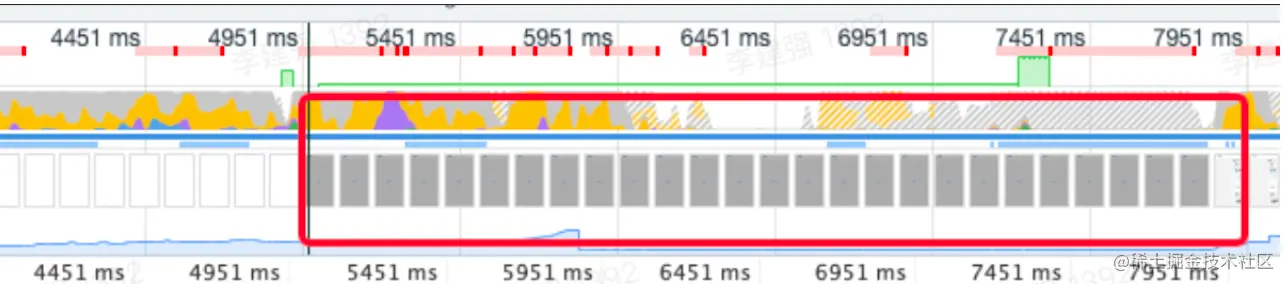
可以看到优化之前loading时长大概3s。 loading时常就是我们的api请求时长。我们再来看一下使用了本地缓存之后的。
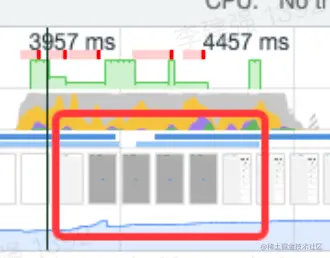
不光首屏加速了,而且api的加载市场已经缩短到300-400ms左右了。 性能大概提升了10倍。 而且我们的api还是通过web worker异步拉取并比较的,所以就算数据有更新,页面的性能也不会有损失。
但是该方法还是只适用于数据不经常改变的请求上。 将一些请求缓存到本地可以大幅度提升性能,给用户提供更好的体验。